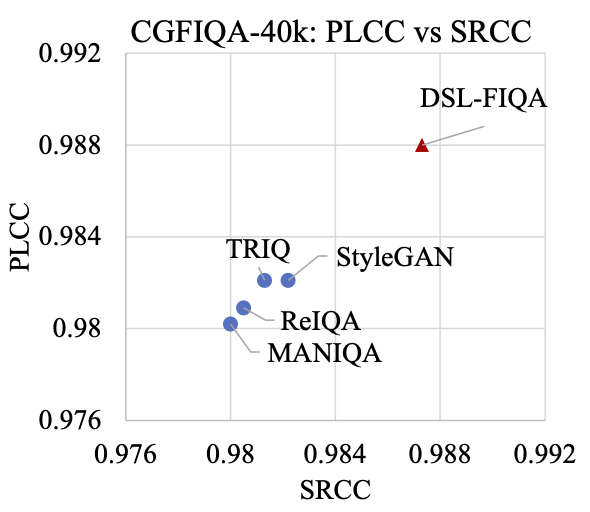
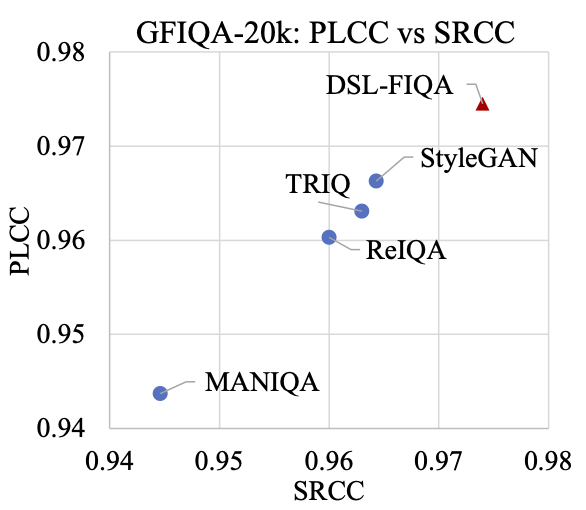
Generic Face Image Quality Assessment (GFIQA) evaluates the perceptual quality of facial images, which is crucial in improving image restoration algorithms and selecting high-quality face images for downstream tasks. We present a novel transformer-based method for GFIQA, which is aided by two unique mechanisms. First, a novel Dual-Set Degradation Representation Learning (DSL) mechanism uses facial images with both synthetic and real degradations to decouple degradation from content, ensuring generalizability to real-world scenarios. This self-supervised method learns degradation features on a global scale, providing a robust alternative to conventional methods that use local patch information in degradation learning. Second, our transformer leverages facial landmarks to emphasize visually salient parts of a face image in evaluating its perceptual quality. We also introduce a balanced and diverse Comprehensive Generic Face IQA (CGFIQA-40k) dataset of 40K images carefully designed to overcome the biases, in particular the imbalances in skin tone and gender representation, in existing datasets. Extensive analysis and evaluation demonstrate the robustness of our method, marking a significant improvement over prior methods.
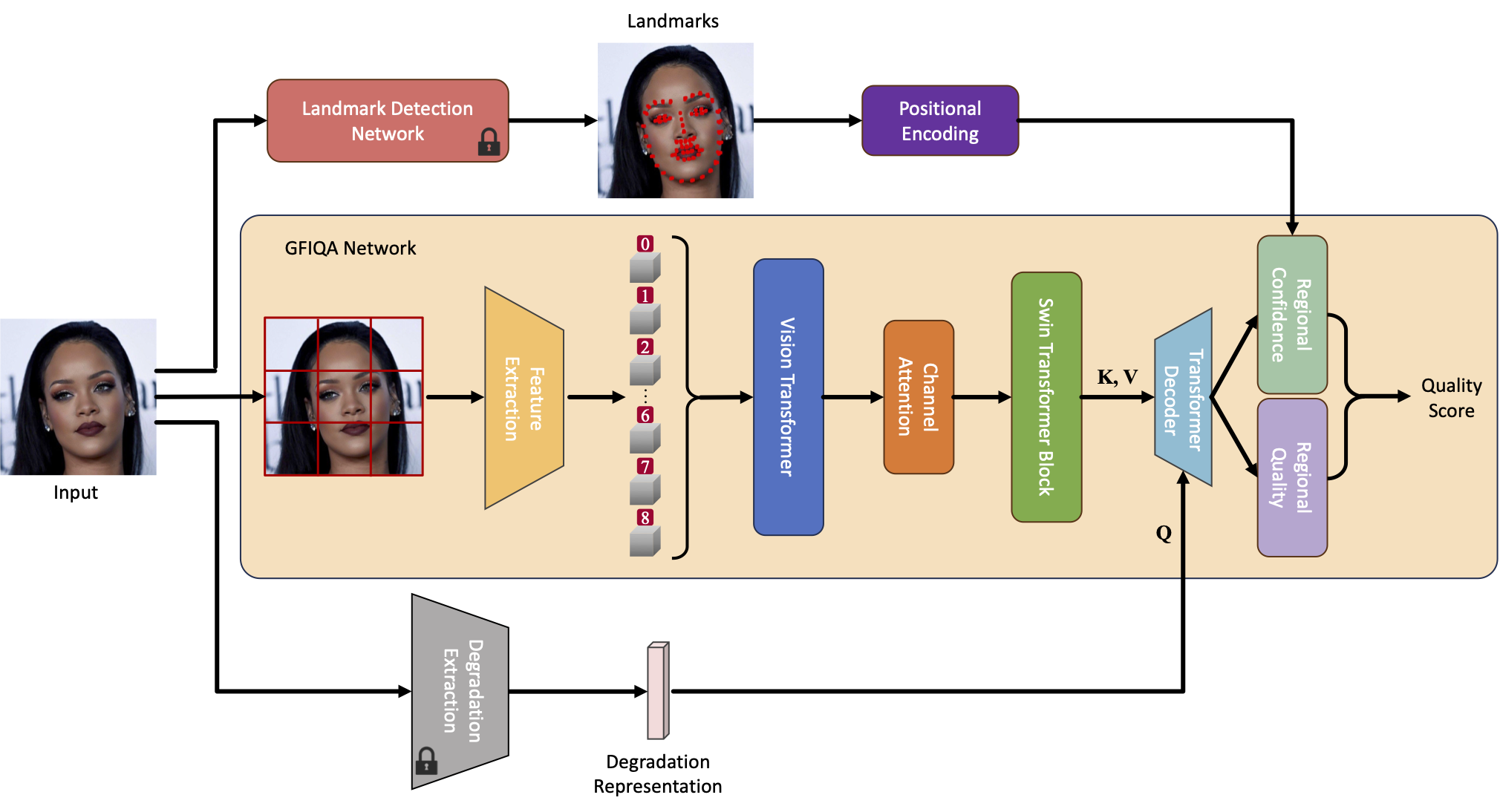
The model contains a core GFIQA network, a degradation extraction network, and a landmark detection network. In our approach, face images are cropped into several patches to fit the input size requirements of the pre-trained ViT feature extractor. Each patch is then processed individually, and their Mean Opinion Scores (MOS) are averaged to determine the final quality score.
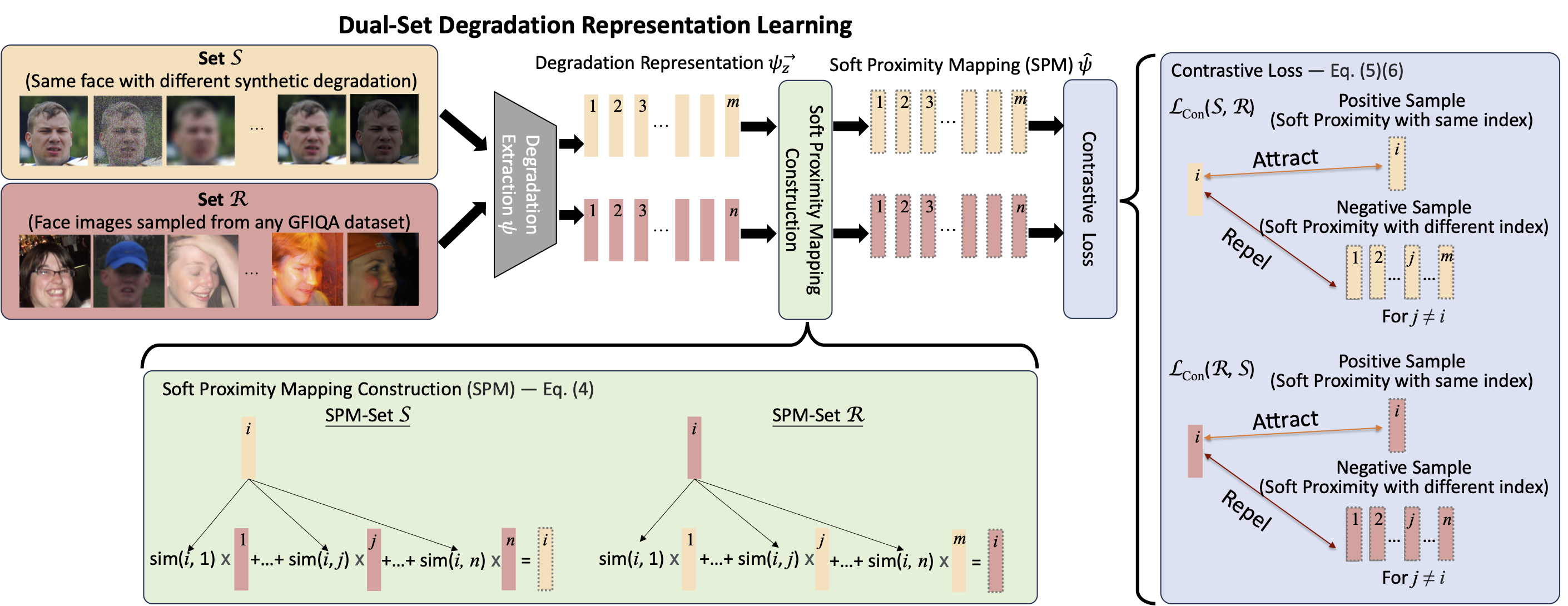
On the left, the process of contrastive optimization is depicted, utilizing two unique image sets. Degradation representations are extracted, followed by soft proximity mapping (SPM) calcula- tions and contrastive optimization, compelling the degradation encoder to focus on learning specific degradation features. The right side emphasizes the bidirectional characteristic of our approach, highlighting the comprehensive strategy for identifying and understanding image degradations through contrastive learning.
To address the limitations and biases of existing datasets for Generic Face Image Quality Assessment (GFIQA) models, we introduce a new dataset named Comprehensive Generic Face Image Quality Assessment (CGFIQA-40k). This dataset consists of approximately 40,000 images, each with a resolution of 512x512, meticulously annotated by 20 labelers. After filtering out a small number of images with unusable content or incomplete labels, we retained a total of 39,312 valid images. CGFIQA-40k is specifically designed to encompass a diverse collection of face images with varied distributions across skin tone, gender, and facial obstructions such as masks and accessories. It aims to provide a more comprehensive benchmark for GFIQA, enhancing the generalization and robustness of state-of-the-art methods.

@inproceedings{chen2024robustsam,
author = {Chen, Wei-Ting and Krishnan, Gurunandan and Gao, Qiang and Kuo, Sy-Yen and Ma, Sizhou and Wang, Jian},
title = {DSL-FIQA: Assessing Facial Image Quality via Dual-Set Degradation Learning and Landmark-Guided Transformer},
journal = {CVPR},
issue_date = {2024}
}